Charting VocaDB & losing my sanity
My recent music post contains some data about what Vocaloid/UTAU/SynthV/etc songs and how many of them ~might be in English. I had initially planned to use VocaDB’s API to pull all Kasane Teto songs and their languages, and thought it would be relatively quick. but I ran into a lot of problems. So, here’s a separate post dedicated entirely to the data gathering!
Exploring the API
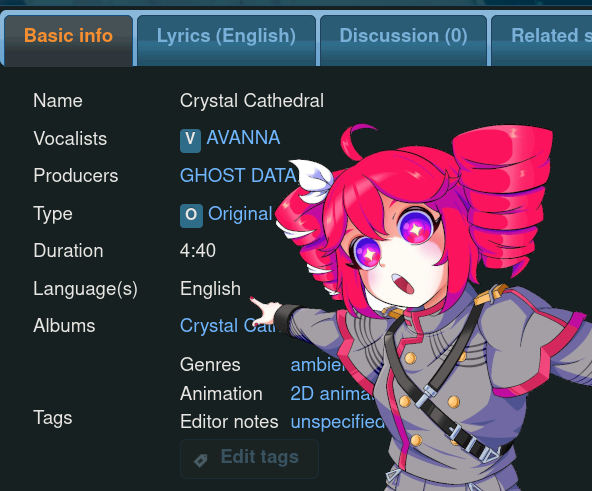
First: VocaDB’s data model. It’s quite extensive but isn’t conducive to easy analyses. When viewing a song, there is a language field that seems to mean “language of lyrics”. That’s what we want!
 (Art by AmarisLunula)
(Art by AmarisLunula)
… but it’s nowhere to be found in any of the responses. /api/songs (search) and /api/songs/{id} don’t return the song’s language, just the language the name is in! Also, it’s… incorrect? This is by all accounts an English song - GHOST DATA is a Texas-based artist, and the title and lyrics are in English - and it even says so on the page above, why is the defaultNameLanguage Japanese?
curl -X 'GET' \
'https://vocadb.net/api/songs/193609' \
-H 'accept: text/plain'
{
"artistString": "GHOST DATA, Jam2go feat. AVANNA",
"createDate": "2018-05-07T20:37:49",
"defaultName": "Crystal Cathedral",
"defaultNameLanguage": "Japanese",
"favoritedTimes": 3,
"id": 193609,
"lengthSeconds": 280,
"name": "Crystal Cathedral",
"publishDate": "2018-04-27T00:00:00Z",
"pvServices": "Youtube, SoundCloud, Bandcamp",
"ratingScore": 15,
"songType": "Original",
"status": "Finished",
"version": 4
}
There is a lang parameter when querying the API… It changes the display language. :|
curl -X 'GET' \
'https://vocadb.net/api/songs/193609?fields=None&lang=Japanese' \
-H 'accept: text/plain'
{
"artistString": "ゴースト データ, Jam2go feat. AVANNA",
What about the /api/songs search endpoint? There is a language filter in the UI (and corresponding languages[] and language parameters in the API)… could we just pull every song, in chunks of 100, from the API for every English and Japanese result? Let’s test in the browser before busting out curl:
Nope.
Oh. Well, if we can’t even get one page to load, I don’t think we’ll get the ~900 pages of 100 or so we’ll need to enumerate all songs.
Back to the drawing board
What if we don’t have to use the API? Is there an offline dump of the database somewhere? Some quick research shows that there’s a person who does database dumps of the site, but exploring their data dumps it doesn’t look like language is included. I was trawling through GitHub and found two other interesting items:
- blueset/vocaloid-database-dump
- This is a database dump (2021…) that was converted from the base dump (!) at
http://vocaloid.eu/vocadb/dump.zip, which looks to actually be kept up to date!! (2026-04 as of this writing)
- This is a database dump (2021…) that was converted from the base dump (!) at
- VocaDB Issue #1979: Other: Add song language field to database dump
- Ah. If this is the aforementioned dump, then still no language field. :/
I downloaded dump.zip anyway to see if there were any other useful fields. It’s a zip of folders which contain json files that definitely look to be database dumps.
.
├── Albums
├── Artists
├── [Content_Types].xml
├── Events
├── EventSeries
├── Songs
│ ├── 0.json
│ │ [...]
│ └── 99000.json
└── Tags
Churning through all of the json with jq and filtering for a specific song ID, we see our familiar friend defaultNameLanguage is now translatedName.defaultLanguage (it’s correct this time)… what’s cultureCodes?
$ cat * | jq '.[] | select(.id==805916)'
{
[...]
"translatedName": {
"defaultLanguage": "English",
"english": "BIRDBRAIN",
"japanese": "トリアタマ",
"romaji": "Toriatama"
},
[...]
"cultureCodes": [
"en"
]
}
(I love that BIRDBRAIN’s Japanese name is トリアタマ.)
Searching through the wiki doesn’t indicate what this list means. Trawling through Github… oh?
You can access more data on lyrics by adding ?fields=Lyrics to the url
The lyrics language is specified in the cultureCodes array
I would recommend to use both the CultureCodes and Lyrics fields (?fields=CultureCodes,Lyrics) and if the CultureCodes array doesn’t contain anything, to fall back to the cultureCodes of the original lyrics. This is the same behavior as the current frontend.
Okay! We’re getting somewhere now. This person suggests using the cultureCodes field, and then it’s also (sometimes) specified in the lyrics object. So we can use cultureCodes, and if it’s empty, fall back to another cultureCodes value if there is a lyrics entry where translationType == "Original".
This might work. Let’s check Crystal Cathedral again…
Fields of interest from the API (specifying the lyrics & cultureCodes fields):
curl -X 'GET' \
'https://vocadb.net/api/songs/193609?Fields=lyrics,cultureCodes' \
-H 'accept: application/json'
{
"artistString": "GHOST DATA, Jam2go feat. AVANNA",
"createDate": "2018-05-07T20:37:49",
"defaultName": "Crystal Cathedral",
"defaultNameLanguage": "Japanese",
[...]
"lyrics": [
{
"cultureCodes": [
"en"
],
"id": 56458,
"source": "",
"translationType": "Original",
"url": "",
"value": "Slowly beneath a crescent blight\nDancing within, a ghostly light\n\nCold glass look on the passerby\nPale arms, she reaches to the sky\n\nThis marbled vessel holds their strife\nHer love will help them find new life\n\nIn weakened limb and broken sigh\nOur Shepherdess will find the light"
}
],
[...]
"cultureCodes": []
}
Fields of interest from dump.zip:
{
[...]
"lyrics": null,
[...]
"names": [
{
"language": "English",
"value": "Crystal Cathedral"
}
],
[...]
"translatedName": {
"defaultLanguage": "Japanese",
"english": "Crystal Cathedral",
"japanese": "Crystal Cathedral",
"romaji": "Crystal Cathedral"
},
[...]
"cultureCodes": []
}
Dang, lyrics is null in the offline dump, and Crystal Cathedral has no cultureCodes values. That means we’re not going to get it without hitting the API, which we’ve already established is infeasible.
Maybe this is enough to go off of, with some clever tricks and inferences.
Local man writes code, balks at it, keeps his day job
I decided to ingest the data into Python by just slurping up all the Song and Artist json files and then fixing up values where we can.
After some frankly terrible and very embarassing Python, some of the worst I’ve ever kludged together (thank god I’m not a SWE), I came up with this:
# infer language
if song.get('cultureCodes'):
inferred_languages = song.get('cultureCodes')
elif len(song.get('names')) == 1 and song.get('names')[0].get('language') != 'Unspecified':
lang = song['names'][0]['language']
if lang == 'Romaji':
inferred_languages = ['ja']
else:
inferred_languages = [str(langcodes.find(lang))]
elif song.get('translatedName') and song.get('translatedName').get('defaultLanguage') != 'Unspecified':
default = song.get('translatedName').get('defaultLanguage')
if default == 'Romaji':
inferred_languages = ['ja']
else:
inferred_languages = [str(langcodes.find(default)]
else:
inferred_languages = None
The logic is essentially:
- We trust
cultureCodes, as it appears to be the most accurate, if it’s present.cultureCodesis an array, and can contain multiple values - hopefully this just means that the song has both English and Japanese in the lyrics.
- If there’s no code, since the next best thing is that the
namesarray has one entry in it, so we take that language and convert it to its two-character code with langcodes. - Otherwise, we use
defaultNameLanguage, as long as it’s specified. The data here is still dirty, as noted above, but we’re working with what we have.
There’s also a tagging system that’s in the offline dump, and there’s an “English lyrics” tag, which we can use too:
if song.get('tags'):
tags = song.get('tags')
# 128: "English lyrics"
if 128 in [tag['tag']['id'] for tag in tags]:
has_eng_lyrics = True
I’ll composite all these signals into a has_any_eng_hint boolean that we can chart with later.
Kasane Teto (Original flavor)
The other interesting part is that the data model for songs is that a Song can have any number of artistIDs, and they can be different types. Both producers and voicebanks are present! Unlike Producers, voicebanks can have a non-NULL baseVoicebankId, which recurses all the way back to a base ID. E.g. for Teto SV2:
Base voicebank: 重音テト (140308)
└── Derived voicebank: 重音テトSV (118397)
└── Derived voicebank: 重音テトSV2 (171066)
That means we need to recurse through each Artist which has a baseVoicebank to find all possible IDs for Teto. Because I hate myself (and I use it a lot at work), I did this in SQL:
WITH RECURSIVE child_voicebanks AS (
SELECT id, baseVoicebankId
FROM artists
WHERE id = 140308
UNION ALL
SELECT a.id, a.baseVoicebankId
FROM artists a
INNER JOIN derived_voicebanks dv ON a.baseVoicebankId = dv.id
)
SELECT id
FROM derived_voicebanks;
After all that, I discovered that the VocaDB API client library I planned to use (but decided against when the API was slooooow) has a utility for converting the dump into a usable data structure that also maps base voicebanks. Seems like you can also work with it offline and it will cache data. Maybe I’ll try it to reproduce my results in fewer lines of code.
Results!
Those are the two interesting parts. I’m not going to bore you with Python matplotlib boilerplate – you can see the graphical results for yourself in my latest music blog post!
Languages associated with Kasane Teto songs from VocaDB (as of 2026-04)
(All song types, including covers)
| Year | English | Japanese | Other |
|---|---|---|---|
| 2008 | 25 | 281 | 3 |
| 2009 | 98 | 777 | 10 |
| 2010 | 170 | 994 | 6 |
| 2011 | 234 | 1057 | 3 |
| 2012 | 209 | 1110 | 11 |
| 2013 | 177 | 1030 | 8 |
| 2014 | 156 | 847 | 7 |
| 2015 | 191 | 908 | 11 |
| 2016 | 157 | 781 | 3 |
| 2017 | 193 | 839 | 7 |
| 2018 | 209 | 1076 | 7 |
| 2019 | 216 | 960 | 10 |
| 2020 | 268 | 1022 | 19 |
| 2021 | 321 | 1286 | 15 |
| 2022 | 297 | 1398 | 11 |
| 2023 | 1266 | 4467 | 99 |
| 2024 | 1899 | 7952 | 266 |
| 2025 | 3129 | 8547 | 473 |
| 2026 | 917 | 1781 | 119 |
Fun fact: “Fictional language” is apparently a language on VocaDB (example).
VocaDB Teto Songs by has_any_eng_hint (as of 2026-04)
(All song types, including covers)
| Year | Not Eng | Likely Eng |
|---|---|---|
| 2008 | 283 | 26 |
| 2009 | 784 | 101 |
| 2010 | 993 | 177 |
| 2011 | 1053 | 241 |
| 2012 | 1118 | 212 |
| 2013 | 1037 | 178 |
| 2014 | 849 | 161 |
| 2015 | 915 | 195 |
| 2016 | 783 | 158 |
| 2017 | 843 | 196 |
| 2018 | 1078 | 214 |
| 2019 | 965 | 221 |
| 2020 | 1032 | 277 |
| 2021 | 1299 | 323 |
| 2022 | 1405 | 301 |
| 2023 | 4508 | 1324 |
| 2024 | 8112 | 2005 |
| 2025 | 8833 | 3316 |
| 2026 | 1861 | 956 |
VocaDB All Songs by has_any_eng_hint (as of 2026-04)
(All song types, including covers)
| Year | Not Eng | Likely Eng |
|---|---|---|
| 2006 | 71 | 22 |
| 2007 | 10295 | 1360 |
| 2008 | 13897 | 3098 |
| 2009 | 19322 | 5640 |
| 2010 | 23873 | 7438 |
| 2011 | 26257 | 8568 |
| 2012 | 29883 | 9628 |
| 2013 | 26849 | 8963 |
| 2014 | 22254 | 8586 |
| 2015 | 21186 | 8824 |
| 2016 | 21508 | 9371 |
| 2017 | 22596 | 9547 |
| 2018 | 24165 | 10358 |
| 2019 | 25346 | 10473 |
| 2020 | 34052 | 12151 |
| 2021 | 45367 | 13646 |
| 2022 | 58490 | 17404 |
| 2023 | 69406 | 17622 |
| 2024 | 72058 | 18573 |
| 2025 | 69177 | 20618 |
| 2026 | 13633 | 4746 |
Final thoughts
DISCLAIMER: This data is in no way definitive. My methods are hacky and gross, and due to the fact that the dump doesn’t contain lyric data, this at best represents a vague estimate of songs which have some relation to English (of course, the data may be wrong, too…). It’s a neat sidequest for a blog post about music I like, and nothing more.
I do think there is more work to be done here, like differentiate based on song type (cover vs original), perhaps find the lyrics and run langdetect on them, or fall back to the API if we don’t have a cultureCode (it’ll probably be fast just to pull one song, though I’d like to not hit the API ~50k times…), but I want to move on so this will have to do for now. Maybe that Github issue will be solved and language will be included in the dump to make this analysis easier.
A better analysis of this data would have all audio and lyric data available for songs, perhaps crunching through songs without written lyrics with an audio-to-text AI model, running a language classifier on the result and outputting a “XX% of this song’s lyrics are English words” value. But even that gets into semantics. Is a loanword written in katakana defined as English? It was once…?! Time is mine’s lyrics are mostly in Japanese, but the chorus is partly in English (but it’s written out with katakana in the MV!). Same TBH’s lyrics are in English, but contain the word テレビ (but it’s an English loanword!)
Work for future me, maybe. With any luck, someone will see this post and get very upset about my methodology, and by nature of posting the wrong answer on the internet, they will come up with a better way.